RAG to Riches: How to Give Your Chatbot a Memory Upgrade
.jpg)
ChatGPT.
We’ve probably all used it once. Maybe to find recipes, answer questions, or to write our essays for us. ChatGPT is an example of a Large Language model (LLM). These LLMs are trained on a massive amount of text and are able to simulate human conversation and answer specific questions. But of course, sometimes these LLMs can’t answer everything. For example, what if we wanted to ask ChatGPT a question about current stock levels for a store? Since that information wasn’t a part of it’s training data, theres no way for it to answer. More often than not, we’ll often encounter situations where ChatGPT isn’t able to answer our question and will even make up and hallucinate an answer!
But fear not! There’s still a way we can use LLM’s to help us answer specific questions it doesn’t know. Retrieval Augmented Generation (RAG).
What is Retrieval Augmented Generation?
Retrieval Augmented Generation, or RAG, is a technique which combines LLMs with external knowledge to help it answer questions it doesn’t know. It involves two key steps, retrieving relevant information from a source, such as a database, based on a users query, and then feeding that information, along with the original query, to an LLM to generate an output.
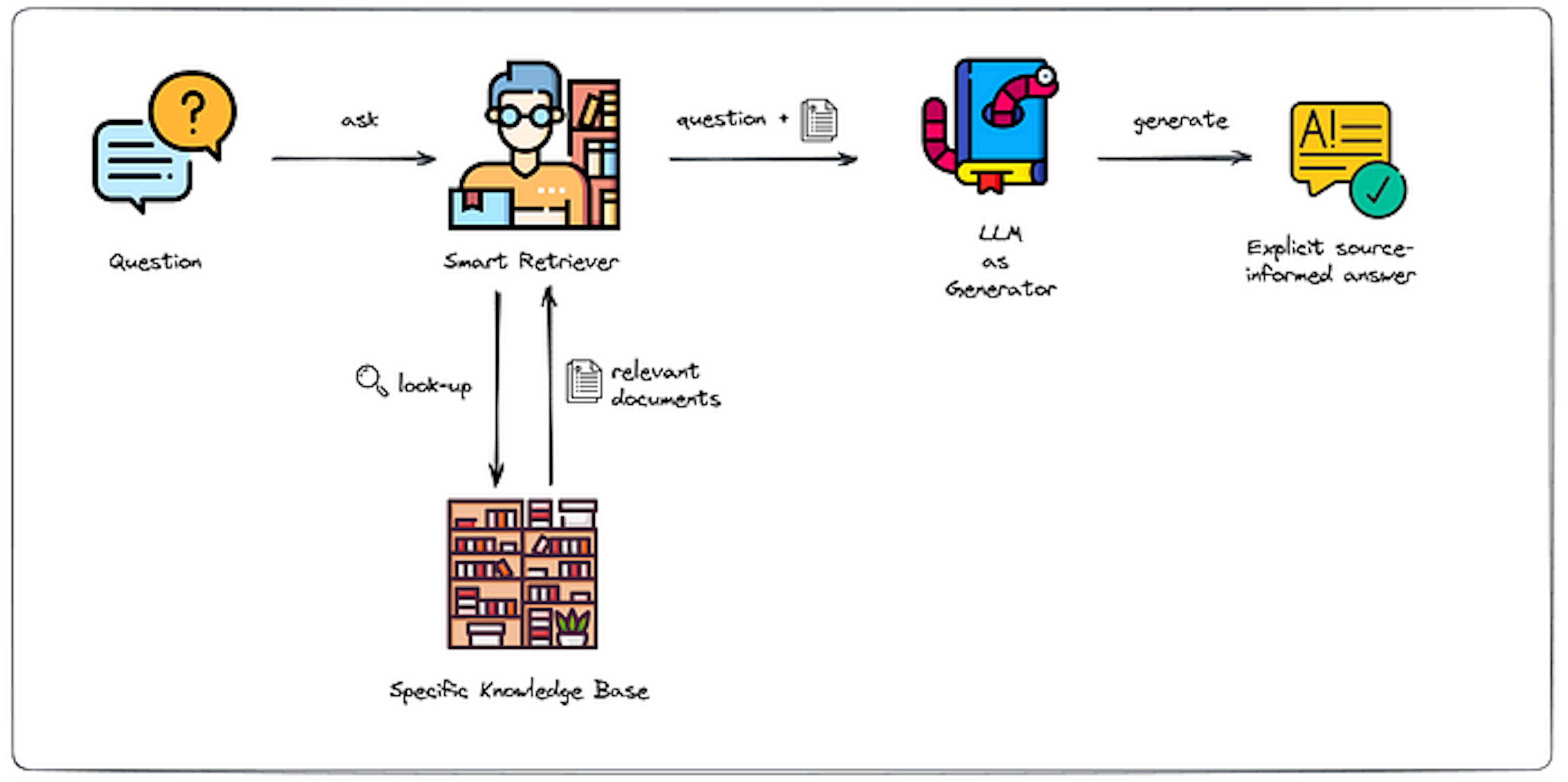
The way RAG retrieves relevant information is by first converting the user’s query into vector embeddings. These embeddings are then searched through a vector database to find the relevant documents. A vector database consists of precomputed vector embeddings of the contexual information. It allows for efficient similarity searches by comparing the vectors it stores, and enabling tasks like document retrieval. For example, if a user inputed the query “How many apples are left in the store”, the query’s vector embedding would be searched in a vector database storing information about stock levels. Relevant documents would then be returned based on similarity comparisons (i.e Cosine similarity, Euclidean distance) with the query. The top three documents retrieved could then bee “Apple stock: 10”, “Pineapple stock: 4” and “Apple juice stock: 10”. Finally, the query along with the retrieved documents would then be passed to a LLM for a generated output.
RAG Applications
So you are probably now wondering, why do we need RAG when we can simply look through the relevant documents ourselves? This is certainly true, however, what happens if the number of documents to search through is extremely high? For example, there could be over one thousand different items stocks in store to search through. When the number of documents is large, exctracting specific information becomes a challenge, like finding a needle in a haystack. By using RAG, we can efficiently search for specific information, and utilise LLMs to summarise that information for us. Some applications of this might include:
- Enchancing customer support chat bots for company specific queries
- Healthcare for retrieving patient specific records
- Personal Assistants
Implementing RAG with OpenAI
Let’s do an implementation of RAG using ChatGPT. For this, we’ll make a chat bot which can answer specific questions about the Australian Constitution. You can download the pdf file of the constitution here .
First, let’s define our chat bot class. We’ll use the LangChain framework to handle our chatbot’s memory of the conversation and API calls, and LLamaIndex for the document retrieval.
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex,SimpleDirectoryReader, StorageContext, load_index_from_storage
import os
from llama_index.core.indices.postprocessor import SentenceTransformerRerank
from langchain.prompts import ChatPromptTemplate
from langchain.memory.buffer import ConversationBufferMemory
from langchain_openai import ChatOpenAI
import warnings
class ConstitutionBot:
def __init__(self, model_name):
load_dotenv()
self.memory = ConversationBufferMemory()
self.llm = ChatOpenAI(
temperature=0,
model_name=model_name
)
We use the load_dotenv function to load our open API key. To use your own API key, make sure you have a ‘.env’ file containing your API key in the same folder. For example:
OPENAI_API_KEY=Your_key_here
Let’s then handle the document retrieval. The first thing we need to do, is convert the Australian Constitution into a vector database. Download the Australian Constitution pdf file and store it in a file named ‘data’ in the same directory.
def retrieve_documents(self, query):
if os.path.isdir("index"):
storage_context = StorageContext.from_defaults(persist_dir="index")
index = load_index_from_storage(storage_context)
else:
documents=SimpleDirectoryReader("data").load_data()
index=VectorStoreIndex.from_documents(documents,show_progress=True)
index.storage_context.persist(persist_dir="index")
The first part of the code checks if there is an existing index directory (vector database). If there isn’t, it will read in the pdf file located in the directory ‘data’, and convert it into a vector store. The VectorStoreIndex.from_documents() function achieves this by dividing the PDF file into specified chunks, and converting those chunks into vector embeddings. The number of chunks and vector embedding model can be defined in the function parameters. For this project, we will just use the default.
We then need to retrieve the most relevant documents based on the query. For this, we pick k = 10, and pick the 10 most similar documents.
def retrieve_documents(self, query):
if os.path.isdir("index"):
storage_context = StorageContext.from_defaults(persist_dir="index")
index = load_index_from_storage(storage_context)
else:
documents=SimpleDirectoryReader("data").load_data()
index=VectorStoreIndex.from_documents(documents,show_progress=True)
index.storage_context.persist(persist_dir="index")
retriever = index.as_retriever(similarity_top_k=10)
nodes = retriever.retrieve(query)
Finally once we have our returned documents, we can perform extra filtering to make sure our documents best match the query. The SentenceTransformerRerank class is used to rerank the documents based on similarity using a pretrained cross-encoder model. This allows for more accurate similarity comparisons compared to basic vector similarity as it considers the interaction between the query and the document together. We will select the top 5 documents after reranking.
def retrieve_documents(self, query):
if os.path.isdir("index"):
storage_context = StorageContext.from_defaults(persist_dir="index")
index = load_index_from_storage(storage_context)
else:
documents=SimpleDirectoryReader("data").load_data()
index=VectorStoreIndex.from_documents(documents,show_progress=True)
index.storage_context.persist(persist_dir="index")
retriever = index.as_retriever(similarity_top_k=10)
nodes = retriever.retrieve(query)
reranker = SentenceTransformerRerank(model="cross-encoder/ms-marco-MiniLM-L-2-v2", top_n=5)
reranked_nodes = reranker.postprocess_nodes(nodes=nodes, query_str=query)
combined_context = "\n".join(node.text for node in reranked_nodes)
return combined_context
Now that we have our retrieved documents, we can handle the querying. To do this, we can do some prompt engineering.
def query(self, query):
context = self.retrieve_documents(query)
final_prompt_str = """
[INST]
Given the following chat history and context, answer the following question.
Context: {context}
Chat History: {chat_history}
{question}
[/INST]
"""
final_prompt = ChatPromptTemplate.from_template(final_prompt_str)
response = self.llm.invoke(final_prompt.invoke({"context":context,
"chat_history":self.memory.chat_memory.__str__(),
"question":query}).to_string()).content
print(f"Constitution Bot: {response}")
self.memory.save_context({"HumanMessage":standalone_query},{"AIMessage":response})
The ConversationBufferMemory.chat_memory and ConversationBufferMemory.save_context functions are used to access chat memory and store chat memory. The memory basically just stores all the previous conversations so ChatGPT can remember what the user and itself said in previous messages.
However, there is one problem with this code. Let’s say our first question is, “Who is the prime minister” and we then follow up with a second question “What does he do?”. When we perform RAG, a vector search for “What does he do” into our Constitution vector store does not make sense at all. There is no context. So to that end, we need to make sure to rewrite our query to make it a standalone question if required. To do this, we can simply do two runs through ChatGPT, one run to rewrite our query, and the second to answer our question after RAG. Once again, we can implement this simply with a bit of prompt engineering.
def rewrite_query(self, query):
rewriting_prompt_str = """
[INST]
Given the Chat History and Question, rephrase the question so it can be a standalone question.
I will give some examples.
---
Example 1: If no chat history is present, then just return the original question
Chat History:
Question: What is the power of the prime minister?
Your response: What is the power of the prime minister?
---
---
Example 2:
Chat History:
Human: What is the power of the prime minister?
AI: The prime minister has many powers
Question: What else can he do?
Your response: What else can the prime minister do?
---
Example 3:
Chat History:
Human: Who appoints the prime minister in a no contest?
AI: The govenor general
Question: What is their role?
Your response: What is the govenor general's role?
---
With those examples, here are the actual chat history and input questions:
Chat History: {chat_history}
Question: {question}
[/INST]
"""
rewriting_prompt = ChatPromptTemplate.from_template(rewriting_prompt_str)
rewritten_question = self.llm.invoke(rewriting_prompt.invoke({"chat_history":self.memory.chat_memory.__str__(),
"question":query}).to_string()).content
return rewritten_question
If there is no history, (i.e it is the first question), ChatGPT will simply return the original question. Otherwise, it will reword the question so it is a standalone question which we can properly peform RAG with. Here is the updated query code:
def query(self, query):
standalone_query = self.rewrite_query(query)
context = self.retrieve_documents(standalone_query)
final_prompt_str = """
[INST]
Given the following chat history and context, answer the following question.
Context: {context}
Chat History: {chat_history}
{question}
[/INST]
"""
final_prompt = ChatPromptTemplate.from_template(final_prompt_str)
response = self.llm.invoke(final_prompt.invoke({"context":context,
"chat_history":self.memory.chat_memory.__str__(),
"question":standalone_query}).to_string()).content
print(f"Constitution Bot: {response}")
self.memory.save_context({"HumanMessage":standalone_query},{"AIMessage":response})
And there you have it! A chatbot which can answer questions about the Australian Constitution. All together, the final code would look something like this:
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex,SimpleDirectoryReader, StorageContext, load_index_from_storage
import os
from llama_index.core.indices.postprocessor import SentenceTransformerRerank
from langchain.prompts import ChatPromptTemplate
from langchain.memory.buffer import ConversationBufferMemory
from langchain_openai import ChatOpenAI
class ConstitutionBot:
def __init__(self, model_name):
load_dotenv()
self.memory = ConversationBufferMemory()
self.llm = ChatOpenAI(
temperature=0,
model_name=model_name
)
def rewrite_query(self, query):
rewriting_prompt_str = """
[INST]
Given the Chat History and Question, rephrase the question so it can be a standalone question.
I will give some examples.
---
Example 1: If no chat history is present, then just return the original question
Chat History:
Question: What is the power of the prime minister?
Your response: What is the power of the prime minister?
---
---
Example 2:
Chat History:
Human: What is the power of the prime minister?
AI: The prime minister has many powers
Question: What else can he do?
Your response: What else can the prime minister do?
---
Example 3:
Chat History:
Human: Who appoints the prime minister in a no contest?
AI: The govenor general
Question: What is their role?
Your response: What is the govenor general's role?
---
With those examples, here are the actual chat history and input questions:
Chat History: {chat_history}
Question: {question}
[/INST]
"""
rewriting_prompt = ChatPromptTemplate.from_template(rewriting_prompt_str)
rewritten_question = self.llm.invoke(rewriting_prompt.invoke({"chat_history":self.memory.chat_memory.__str__(),
"question":query}).to_string()).content
return rewritten_question
def retrieve_documents(self, query):
if os.path.isdir("index"):
storage_context = StorageContext.from_defaults(persist_dir="index")
index = load_index_from_storage(storage_context)
else:
documents=SimpleDirectoryReader("data").load_data()
index=VectorStoreIndex.from_documents(documents,show_progress=True)
index.storage_context.persist(persist_dir="index")
retriever = index.as_retriever(similarity_top_k=10)
nodes = retriever.retrieve(query)
reranker = SentenceTransformerRerank(model="cross-encoder/ms-marco-MiniLM-L-2-v2", top_n=5)
reranked_nodes = reranker.postprocess_nodes(nodes=nodes, query_str=query)
combined_context = "\n".join(node.text for node in reranked_nodes)
return combined_context
def query(self, query):
standalone_query = self.rewrite_query(query)
context = self.retrieve_documents(standalone_query)
final_prompt_str = """
[INST]
Given the following chat history and context, answer the following question.
Context: {context}
Chat History: {chat_history}
{question}
[/INST]
"""
final_prompt = ChatPromptTemplate.from_template(final_prompt_str)
response = self.llm.invoke(final_prompt.invoke({"context":context,
"chat_history":self.memory.chat_memory.__str__(),
"question":standalone_query}).to_string()).content
print(f"Constitution Bot: {response}")
self.memory.save_context({"HumanMessage":standalone_query},{"AIMessage":response})
if __name__ == "__main__":
bot = ConstitutionBot("gpt-3.5-turbo")
print("Hi! I'm Constitution Bot! I know everything about Australia's Consitution. Ask me a question :) \nType 'exit' to end the conversation")
while True:
query = input("Enter your question:")
if query.lower() == 'exit':
break
bot.query(query)